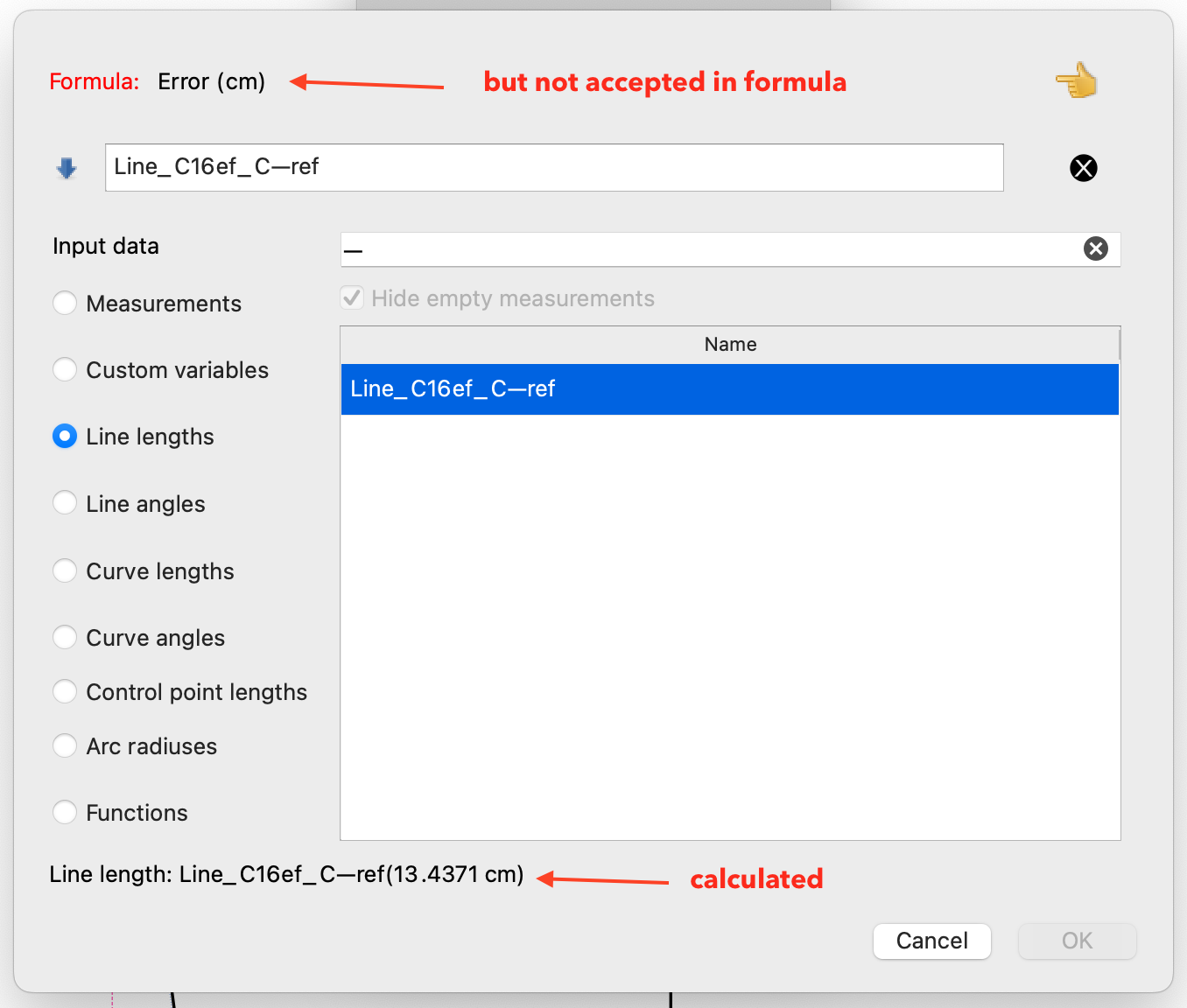
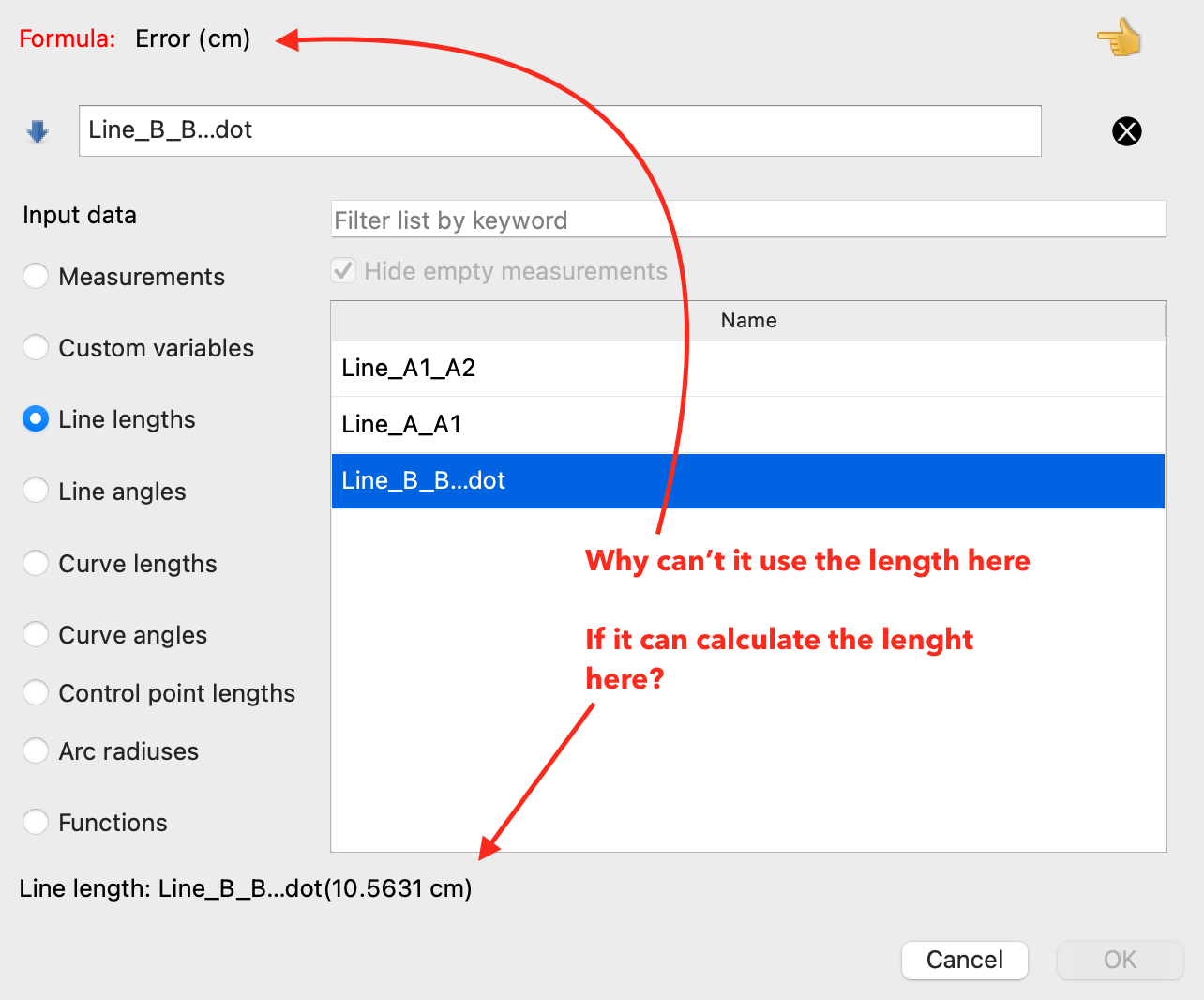
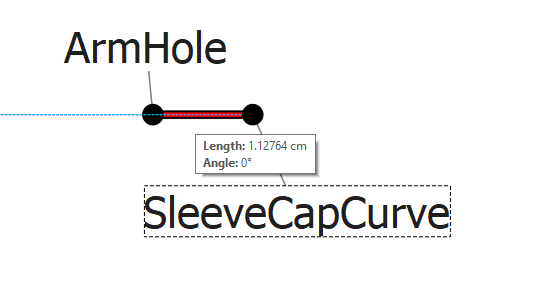
It looks that the lenght of the line is correctly calculated but not accepted in the formula calculation.
My guess is because the ~ in the point name.
I tried also with en dash and em dash: same result.
See screenshot: where I used an EM dash
What characters can I use apart to underscores? I find confusing that the underscore is used as separator in the point name and also in line names and spline names.
I tried Camel case but to me is not that legible.
If I could use a tilde or en dash inside a point name I could parse more easily when choosing an existing line lenght.
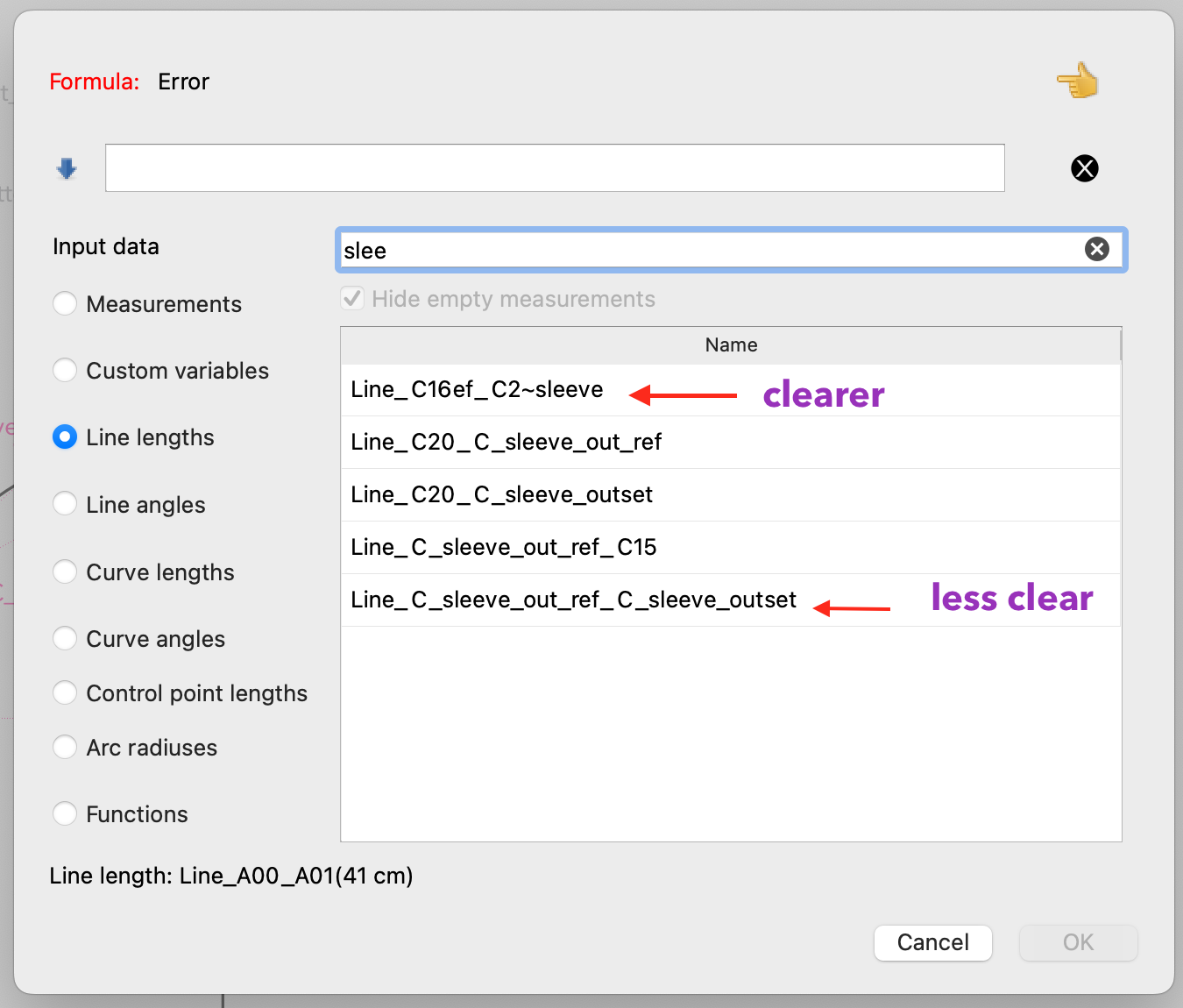
In the example below I can see more easily that the line is between C16ef and C2~sleeve and not between C16ef_C2 and sleeve
The less clear line in the example could be a line between:
I don’t know why the inderscore should be confusing… but I can get back to you with a complete list of valid chars when I’m at the laptop with access to the code.
In any case if the fx dialog displays the red Error: there is a syntax error or invalid char in a variable name. The valid chars are NOT open to change, as they are defined in the mathparser. If it’s a math operator it’s not a valid char for a name. The tilde is not valid as it’s the bitwise NOT operator.
Hey… BTW… if anyone finds any chars that are valid as a point name, but are not valid when the point name is used in a formula - let me know so I can try and fix that so you can’t use them in the point name. I know I found ~\ and the $ to be 3 such chars.
En dash, unicode U+2013: –
Em dash, unicode U+2014: —
Bullet. unicode U+2022: •
are such characters, which doesn’t make sense to me as they have no mathematical meaning and are used in good typography, also they are not listed here
A Case for different dividers in point names
Elaborating from the example in the original post:
Sometimes I name my points with names related to what the point are:
waist_reference
anchor_labe01
anchor_label02
sleeve_outset
sleeve_outset_ref
etc..
If the underscore is the only separator in the string it can be difficult to understand if it’s separating between two part of a point name or it’s separating two point:
example: Line_armscye_fitted_neck_back_point can be a line
between armscye_fitted and neck_back_point
between armscye and fitted_neck_back_point
C_sleeve_out_ref_C_sleeve_outset can be a line:
between C_sleeve_out and ref_C_sleeve_outset
between C_sleeve_out_ref and C_sleeve_outset
Having only one divider forces to workarounds, such as putting a prefix in front of every point or constructing a sort of positional grammar of point qualifier, it’s possible, but I prefer to be able to name points more freely.
Understanding the logic
But # is accepted in point names and also works in formulas and ~ is not there, even though it doesn’t work in formulas.
Is this list derived from the mathparser (which cannot be changes as I understand) and then you construct a regex pattern to refuse the same characters in point name?
I would find that rather tedious… not to mention I found it gets really messy in the workspace.
I never got too caught up in a complex naming convention for points. To me “label” would redundant… anchor1, anchor2… is what I use. I don’t need the pattern to look like C++ code. But that’s me.
Just a thought… the point names are not translated and if you’re sharing a pattern with some who doesn’t speak the language, the point names may be meaningless. For ex: other than Neckline and Bust2 - I have no idea what this means and would rather just see A1, A2, etc…
Your’e probably correct on the #, but the # is used for Custom Variable names and I would not use with point names to avoid confusion.
Which means it should be there. Oversight of the orginal dev.
Yes. It’s in the math parser AND the pattern schema. The math parser parses the whole formula string so it needs to identify what is a variable name and what are math op’s (and functions). If you put math ops in the name it takes it as an operation and the formula will be invalid. And it’s not so much that the regex can’t be changed… you have to take into account what else in the app will be affected AND account for NOT breaking existing patterns. For example… if a user for some reason used the ~ as a point name and for some reason that point was never used in a formula to cause an error AND then we change the schema / math parser to remove it as a valid char - the pattern will break. It’s easy to add to the schema, quite another to take away… or as in this case vice versa as the regex is what you can’t use. Which is why there are probably some chars that are valid in the point name when they shouldn’t be for as to remove them may cause other issues. Ideally we should have a way to warn a user when loading a pattern with invalid chars in a point name in a pattern and ask what to replace it with. Kinda of like when you embed a font in doc, and then someone tries to open it on a system without that font, and they get a choice of what to replace that font with.
I tried to explain some the use case why I found this more convenient, as it’s similar to comments in code, where even for yourself it can be useful, after you don’t open a file for some time.
It’s also way easier to select them from the list when you insert them in formulas.
If they see meaningful names but don’t know the language they will have to reverse engineer the pattern.
If they see just C1, C2 etc, … they will have to reverse engineer the logic of the pattern.
I might as well use meaningful name for me, at least someone will have life easier!
This is not really the scope of this post, everyone can work as they see fit.
What I’m trying to understand is what characters I can use as separator, that will be accepted in full.
It looks to me that the math parser is stricter than the regex pattern.
For eample, I tried the
And it’s accepted in the point name but does’t work in the formula.
Since there are thousands of symbols, and every time I try a unicode symbol it doesn’t compute, it looks the math parser plays by only considering some characters as correct, instead of forbidding a set, like the regex string is doing.
I can’t parse this string in https://regex101.com but I guess there is more to it than a simple regex string.
So, the original question remain: is there a way to know which characters will work in formulas and in point names?
but when using characters not accepted by the math parser Seamly is still capable of calculating the lenght of the line, even if one of two points has “illegal” characters in the name.
Why can’t it use it in formulas?
Because the math parser isn’t paying attention to the name, unless it’s written in a formula, (Based on what I’m seeing in the XML, so I think I got that right.)
Why I never noticed the OP issue in spite of sometimes using a similar naming scheme: instead of sleeve_outset I’d put SleeveOutset so as to set the words apart without whitespace. A habit gained from not liking to remember quotation marks when opening directories in my linux terminal.
The ability to enter a comment for a drawing object would be very useful. When you look back at something you did months ago, comments would help where the formula is not immediately obvious.
That’s doable, but quite a job, as all the 50+ tool dialog forms / classes, tool classes, schema, and pattern parser need to be updated. Been there done that more than once. Oh… and then you have to decipher the Properties browser to add a new property for each tool there as well.
In the first post I said that I tried Camelcase (I thinks this is waht you do) but it doesn’t work always, especially with some letter sequences…
I think the math parser works the opposite way the regex string for point names. The parser has a list of what accepts, the regex forbids.
Because of that, I could spend days trying every suitable unicode character to see if it works, while if I could know the logic of how the parser works (does it use a classification like this?) I could try having a smaller number of cases.
What frustrates me is that I never asked or wanted any code change about this problem. I just would like one suitable separator apart from underscore.
I’m trying to tell you there isn’t one. Just FYI… I spent the time (given the fact that the math parser is more complex than would seem) to be able to answer your question with a very precise answer. So you’re welcome.
In a nutshel here’s what you can use in a Point or Custom Variable name that the math parser allows:
As you can see the ONLY allowable name chars in the math parser besides the unicode letters are the numbers 0-9, and “_@#”.
PERIOD. All the other chars are reserved for math parser operators. The underscore as a seperator, the @ for measurments, and # for variables. I stand by my assertion - this can’t be changed. I don’t know what else to tell you.
Should we fix the fact that chars can erroneously be used in a Point name that conflict with the math parser? Perhaps, but we would have to make the decision if doing so out weighs the small chance it breaks existing patterns.
I would further add that the regex previously posted does in fact restrict the use of the chars contained in it when you try to use them in a Point name. Don’t ask me why some chars such as the tilde are not in it. I didn’t port the math parser.
first of all, thank you for spending the time to look into it. I appreciate it.
I would have done it myself but this was beyond my level of skills.
I accept the limitation but I wonder what was the motivation behind this strange limitations by whoever designed the Math parser.
I think a good compromise would be alerting that the pattern contains characters in point names that won’t work in formulas. Just an alert, so previous patterns will not be broken.
Another thing, since you can use @,# in point names, I’m wondering what is the risk of confusing the Math Parser or crash the program or break the pattern if you do use them.
Is it possible that a formula with measurements, variables AND points with @ and # in their names breaks the Parser?
If so there is another reason for including an alert of some sort.
Not strange at all, because when you take away all the chars that are “math” related - operators and grouping brackets like () - what’s left? Without some complex AI how is the parser supposed to know if a char token is to be interprted as part of a name or as an operator?
For ex: Given A1-A2-4… is it a Point name A1-A2 minus 4 OR is it variable A1 minus A2 minus 4?
No. You can use the @ and # in point names. The math parser looks for “names” and opertaions. The name can be a point, variable, or measurment. But like I said the @ is used as a prefix for measurments and # for custom variables.
Oh… I should add that it should be obvious that you can’t use the math Function names as a Point name. They will be rejected.
Otherwise known as “CamelCase”. In your examples - UpperCamelCase… rather than lowerCamelCase.
It’s a style of writing variable names in code. Generaly you use the underscore when all the chars are UPPER_CASE or lower_case. Out of longtime habit I avoid caps and spaces in file names so the underscore makes names easier to read… like pattern_piece_dialog.cpp.
Otherwise camel case is used lot in the app source code. UpperCamelCase for class names, lowerCamelCase for methods and variables. In the case of class members, variables will often be named with the prefix m_ for member… and continue in camelCase… like m_lineWeight.
And that concludes todays lesson on underscore and camel case. LoL